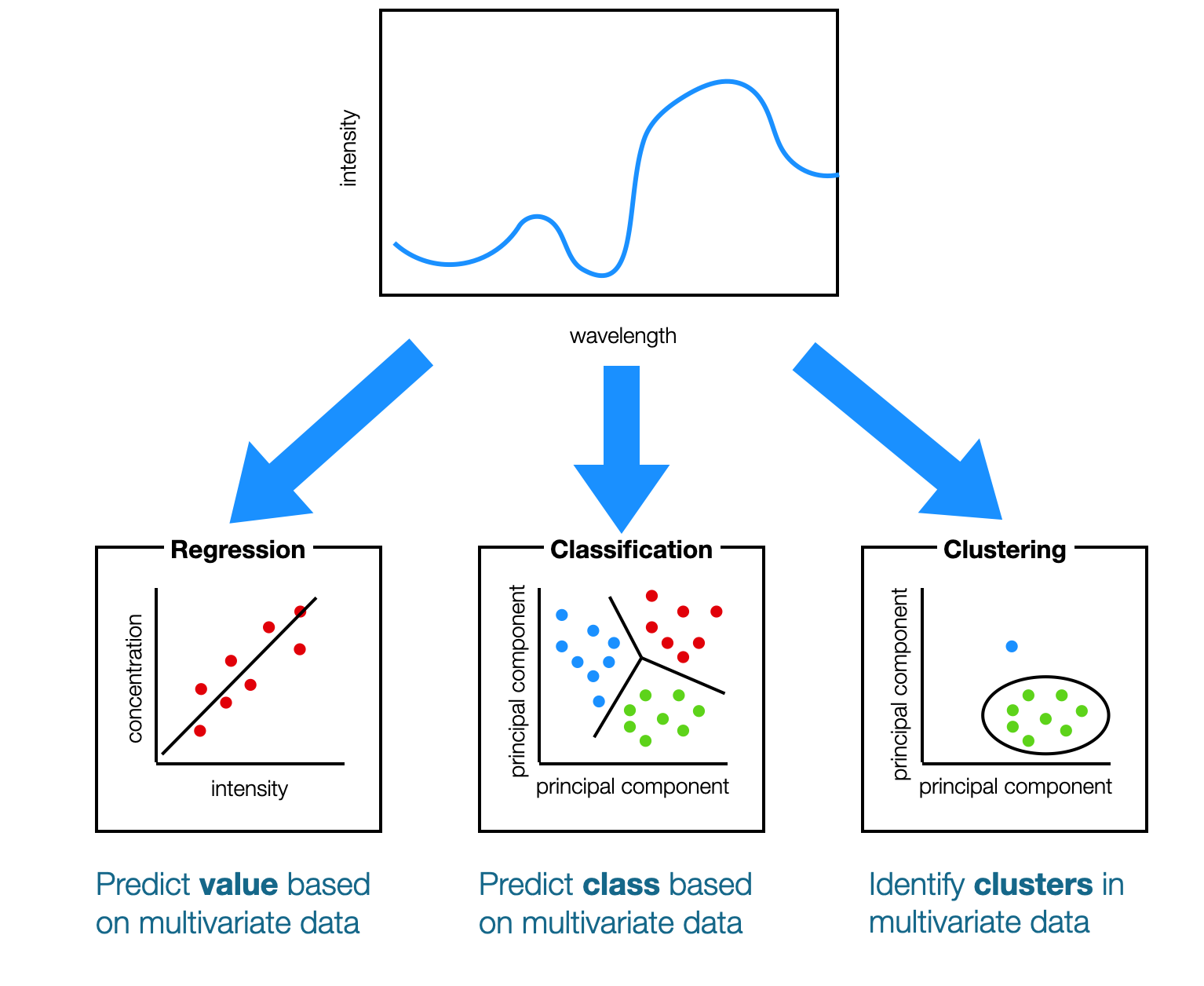
Different types of Machine Learning models.
Machine learning, at its heart, is the derivation of relationships and information from data. These relationships are represented in the form of models, which are then applied to understand new data. There are many different types of models, of course, but they generally fall in one of three categories:
- regression
- classification
- clustering
They each have their special uses, which we will discuss below, but they all take advantage of the high dimensionality of multivariate data and the covariance of those variables.
In Chemistry, this multivariate data is often in the form of spectra (e.g. UV-visible, infrared, NMR, mass spectra), as in the example above. There, absorption intensities at multiple wavelengths are used to predict various things: a concentration value, class membership or the presence of a cluster.
Regression (supervised)
Regression models relate input data to one or more numerical output values. For example, in the figure below the intensity at one wavelength from the spectra are related to the concentration of a particular species.

This is a very simple example, of course, since only one variable (i.e. intensity at one wavelenghth) is used. This sort of (univariate) linear regression is very common in Chemistry, but it leaves a lot of the information “on the table”, so to speak. There is almost always additional information contained by the intensities at other wavelengths, so why not include those, too? That’s what multivariate regression does.
Types of multivariate regression models
There are many, many different kinds of regression models, including things like multivariate OLS (ordinary least squares), lasso/ridge/elastic regularization, PCR (principal components regression), PLS (partial least squares), GPR (Gaussian process regression) and neural networks, just to name a few.
Regression models are supervised
Regression models are supervised models because they are trained using a dataset for which the values to be predicted are already known somehow. In the example, above, this means that there is a training dataset consisting of spectral intensities and the corresponding concentration.
Classification (supervised)
The aim of classification models is to relate input data to membership in a class or classes. Think of these classes as groups or categories. In the example, below, spectra are used to predict which class a sample belongs to (red, green or blue).

Notice that, as opposed to the regression example above, here we are using information from all of the wavelengths in each spectrum. Yet, we are still representing each sample (each colored dot) with just two values, the so-called “principal components.” So, we’ve reduced the dimensionality from however many wavelengths we had in each spectrum to just two! While beyond the scope of this overview post, what we have used here is called “principal components analysis,” and you can read more about it in this post.
In the example above, three black lines are drawn representing the boundaries between the different classes. These lines represent the model, and any new data can be classified by determining where they fall (more preciesly, where the dot representing the spectrum falls) with respect to these lines.
Types of multivariate classification models
As with regression, there are many, many different types of multivariate classification models available. Some of the more common ones are: k-nearest neighbors, linear discriminant analysis, PLS-DA (partial least squares discriminant ananlysis), decision trees, bagged trees, random forest, boosted trees and SVM (support vector machines).
Classification models are supervised
Like regression models, classification models are supervised, too, meaning that they must be trained using data for which class membership has been determined already.
Clustering (unsupervised)
Unlike regression and classification, clustering models do not require training data. Therefore, they are considered _unsupervised” models. The goal is to find clusters of samples that are similar to each other by some measure. There are many choices for what this measure can be, but it usually represents some measure of distance in multi-dimensional space; samples that are close to one another constitute a cluster.
In the example below, the green points are close to one another and make up a cluster. The blue point is far away from the cluster and is therefore not considered to be part of it.

Hard vs. soft clustering
In clustering, samples can be assigned to a single cluster, in which case we call this “hard” clustering. However, it is also possible to assign to each sample a membership “score” for each cluster; thus, it’s not an all-or-nothing proposition as far as which cluster a sample belongs to. We can represent partial membership in multiple clusters with the membership score providing additional information.
Types of multivariate clustering models
Hard clustering
Some of the more common hard clustering models are: hierarchical clustering analysis, k-means and DBSCAN (density-based spatial clustering of applications with noise).
Soft clustering
Common soft clustering models include: Gaussian mixture models and fuzzy c-means.